Welcome to Neilpang's Blog!
记录生活,分享知识,传播乐趣-
设置sslkeylogfile支持wireshark解密ssl内容
我们知道 wireshark 可以直接解密以 RSA 为密钥交换算法的 ssl 流量. 只需要给 wireshark 设置 ssl 证书私钥就可以了.
但是 RSA 交换算法已经普遍被禁用了, 对于主流的 DH 或者 ECDH 交换算法, wireshark 无法解密.
但是, 工业上的一个实际标准可以使 wireshark 解密这些ssl 链接:
设置
SSLKEYLOGFILE环境变量.参考: https://www.comparitech.com/net-admin/decrypt-ssl-with-wireshark/
简单的讲, firefox 和 chrome 在运行时会检测这个环境变量
SSLKEYLOGFILE, 它指向一个文件, firefox会把 DH 交换的私钥保存到这个文件里面.在Wireshark 中, 有个设置可以指向这个文件, 这样 wireshark 就可以动态的在这个文件中查找相应的 DH key, 并成功解密ssl 链接.
目前主流软件都支持这种方法(chrome, firefox, openssl, python, nodejs), 但是支持细节有所差异.
比如, nodejs不使用这个环境变量, 而是在
tls.TLSSocket上暴露一个on("keylog", (line)=>{})事件, 用户可以接收这个时间, 并保存到文件中.
-
Install Cloudflare Cli Wrangler
https://github.com/cloudflare/wrangler#-installation
curl https://sh.rustup.rs -sSf | sh apt-get install pkg-config libssl-dev cargo install wrangler
-
安装php Composer
用下面的命令安装:
curl -sS https://getcomposer.org/installer | php mv composer.phar /usr/local/bin/composer值得注意的是, php 的
composer是一个开发时的工具, 当用它解决完依赖以后, 应该把依赖都保存.安装依赖的方法:
// vendor:厂商名 package:包名 composer require vendor/package
-
Docker Compose 的网络模式
在 docker-compose 的原始版本中, 创建出来的服务都是全局的, 也就是说同一台机器上的所有 docker-compose 产生的container是可以互相访问的, 只要通过ip 就可以. 如果通过
link也可以通过name访问.在 docker-compose 的
v2和v3版本中, 每一个docker-compose所创建的所有服务(container) 共享同一个网络. 同一个网络内的服务之间可以通过name互相访问. 但是不同docker-compose产生的服务之间默认是不能访问的.要想解决这个问题, 官方推荐的做法是让需要跨网络访问能力的conainer 加入到多个网络中. 参考这有说明:
https://docs.docker.com/compose/networking/
如果在一些简单的情况下, 我们不需要这么复杂, 只需要让
docker-compose不创建独立网络, 而像以前一样使用系统的默认网络就好. 只需要加入:network_mode: bridge像这样:
version: "2.1" services: app: image: ubuntu:latest network_mode: bridge参考: https://stackoverflow.com/questions/43754095/how-to-join-the-default-bridge-network-with-docker-compose-v2
-
我开始喜欢_vscode_了
最近用上 vscode, 我开始喜欢上它了.
轻量, 插件丰富, 调试简单. 基本上可以做到 任何位置, 任何文件 开始调试.
-
远程调用selenium
通过 selenium 调用 firefox, 一般可以有两种方式:
- 本地调用. 通过 webdriver 直接调用本机上安装的firefox. 这种方式最简单直接. 坏处是你的代码和firefox 必须跑在同一台机器上.
- 远程调用. 在一台机器上跑 selenium server, 然后在另一台机器上用 RemoteWebdriver 直接操作这个 selenium server. 这个 server 中可以支持 firefox, chrome 等等. 最棒的是, 这个 server 可以跑在 docker 中.
今天主要记录一下第二种方式.
官方提供了一系列镜像: https://hub.docker.com/u/selenium/
仓库在这里: https://github.com/SeleniumHQ/docker-selenium
这些镜像基本上分为三类:
- standalone 类, 就是我们刚才说的server
- standalone debug 类, 跟 standalone 功能一样, 但是其中安装了 vnc server. 你可以用 vnc 直接连上去实时查看到firefox 的运行情况.
- node 和 hub, 它们可以构建集群.
这里我们选在第二类, 就是运行起来后用vnc可以看到结果的.
先起server:
docker run -d -p 4444:4444 -p 5900:5900 selenium/standalone-firefox-debug:3.141.59-neon这里有两个端口:
4444是server 的控制端口, 可以用浏览器直接访问.5900是 vnc 的端口. 可以用vncviewer直接连接. 对了vnc的默认密码是secert(密码可以改, 请参考官方的说明: https://github.com/SeleniumHQ/docker-selenium).登陆完成可以看到 桌面了:
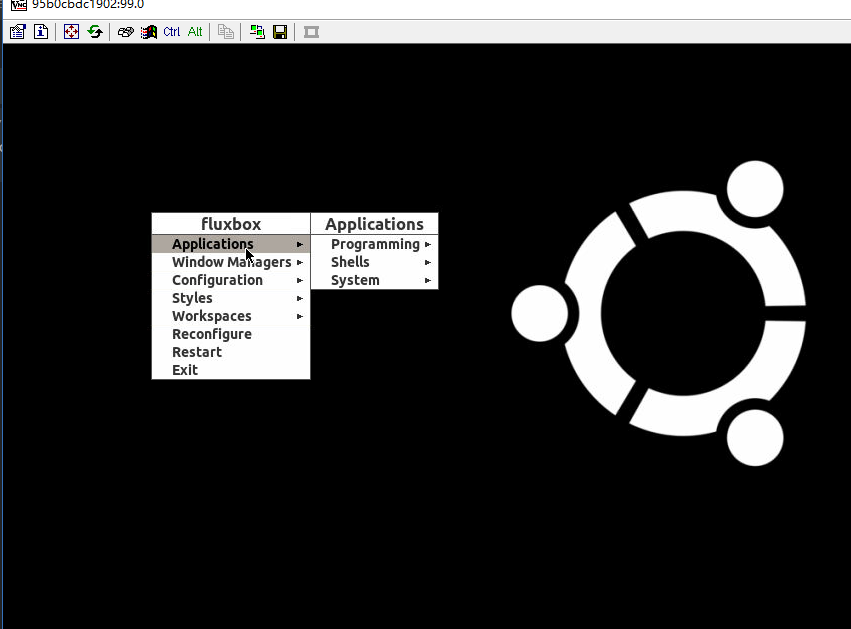
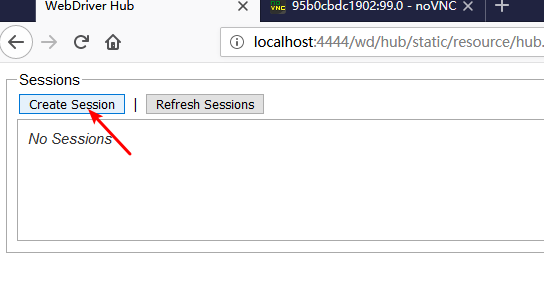
现在我们浏览器打开: http://localhost:4444/wd/hub/static/resource/hub.html
然后创建一个 firefox 实例吧:
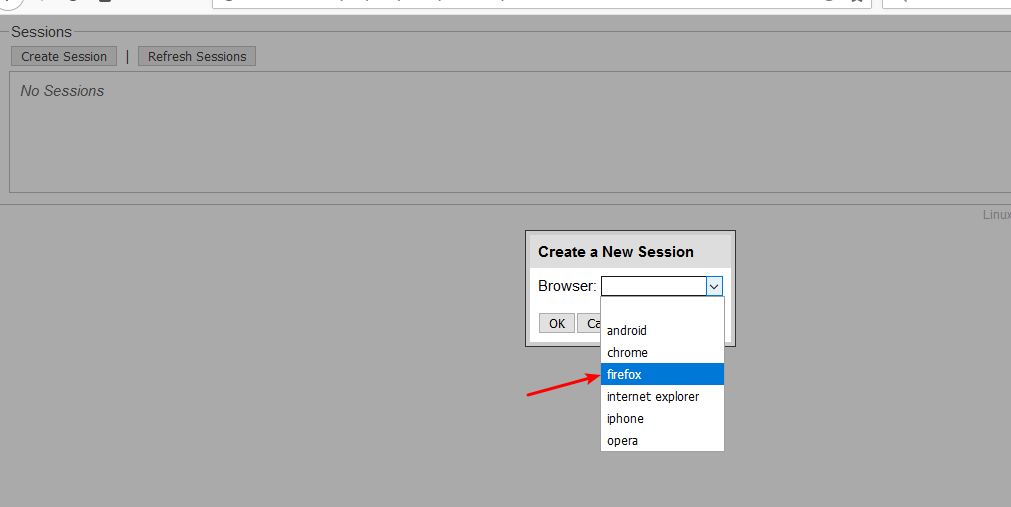
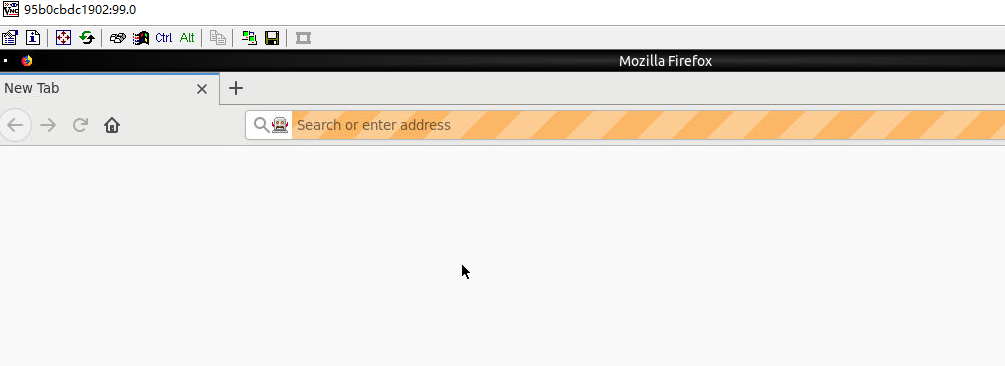
再回到 vnc 的桌面就可以看到了:
前面只是开胃菜. 接下来我们看一下如何编程访问.
在本机安装好
python以及selenium模块以后. 运行以下代码:from selenium import webdriver; from selenium.webdriver.common.desired_capabilities import DesiredCapabilities def test(): host = "http://localhost:4444/wd/hub"; capabilities = DesiredCapabilities.FIREFOX; driver = webdriver.Remote(host, capabilities) driver.get("http://www.baidu.com") test()你可以单步调试, 此时再看 vnc 桌面:

就到这吧, remote driver 和本地的 webdriver 接口一样. 所以用法是一样的. 其他的不罗嗦了.
到目前为止, 一切都很完美, 除了一点, 就是需要 vnc 客户端来访问桌面. 下一篇我们介绍用 novnc 来代替 vnc 客户端访问.